We asked an AI system 100 biomedical research questions, 50 broad overview questions and 50 specific technical questions, and tracked every paper it cited. We verified each against PubMed, retrieved citation counts, built a citation-matched control group of 172 topically similar papers the AI did not cite, and ran statistical tests to identify what actually predicts AI citation.
The question: beyond citation count, do content features like title structure, abstract format, or open access status independently predict whether AI cites a paper?
The answer surprised us: no. Once you control for citation count, none of the content features we measured, open access, structured abstracts, declarative titles, specific entities, significantly predict AI citation. The only signal that matters is how many times humans have cited the paper first.
AI citation is almost entirely explained by human citation count. In a case-control analysis comparing 167 AI-cited papers against 172 citation-matched controls from the same topics, no content feature, open access status, abstract structure, title type, or entity density, independently predicted AI citation (all p > 0.05). Citation count alone explained 12.4% of variance; adding all content features increased this by just 1.5 percentage points. You cannot optimise your way into AI citation. You have to write impactful research that humans cite first.
Why This Matters Now
AI systems are becoming a primary way researchers discover papers. When a graduate student asks ChatGPT or Claude to explain a biological mechanism, the papers cited in that response receive direct attention. Unlike Google Scholar, where hundreds of papers appear in search results, AI typically cites 1–3 papers per answer. The selection is brutal.
A growing literature on generative engine optimisation (GEO) claims that content structure, entity density, and formatting can boost AI citation, but this work has focused on commercial web content. Academic papers operate under different rules. We designed this study to test whether content features actually predict AI citation for research papers, using proper controls and statistical tests.
Methodology
We constructed 100 biomedical research questions spanning five subfields: immunology, oncology, neuroscience, genetics, and cell biology. The questions were split into two categories:
- 50 broad overview questions: "How does CAR-T cell therapy work?", "What are the genetic risk factors for Alzheimer’s disease?"
- 50 specific technical questions: "What is the IC50 of venetoclax in CLL cell lines?", "Which antibody clone works best for PD-L1 IHC in NSCLC?"
Each question was submitted to Claude (Anthropic). Every cited paper was verified against PubMed by DOI lookup, and citation counts were retrieved via the elink API.
The critical addition: citation-matched controls
An initial analysis without controls appeared to show strong associations between content features and AI citation. But a reviewer would immediately object: are these features actually predictive of AI citation, or are they just proxies for high citation count?
To address this, we built a citation-matched control group. For each AI-cited paper, we used PubMed’s related-articles algorithm to find a topically similar paper from the same field that the AI did not cite, matched as closely as possible on citation count. We then filtered both groups to include only papers with abstracts (removing editorials, letters, and commentaries). This yielded 167 AI-cited papers and 172 matched controls.
This case-control design isolates the question: among papers with comparable citation counts and topical similarity, what distinguishes the ones AI cites?
100 biomedical questions | 50 broad + 50 specific | 5 subfields
AI-cited papers: 167 (verified on PubMed, with abstracts)
Citation-matched controls: 172 (same topics, comparable citations, not AI-cited)
Statistical tests: Chi-square for categorical, Mann-Whitney U for continuous, logistic regression for multivariate
AI system: Claude (Anthropic) | Single session, no retrieval augmentation
Data collected April 2026. Citation counts from PubMed elink API.
Limitations (stated upfront)
- Single AI system. We tested Claude. ChatGPT, Perplexity, and Gemini may differ. Perplexity uses live search, which is a fundamentally different citation mechanism.
- Training data citations, not live search. These results reflect what the model learned during training, not real-time retrieval.
- Sample size. 167 vs 172 papers provides adequate power for large effects but may miss small ones. The 6pp differences in some features could be real but undetectable at this sample size.
- Imperfect citation matching. Our controls have a median of 493 citations vs 1,219 for AI-cited papers. The match is closer than random (median 35) but not exact. Residual confounding by citation count remains possible.
- Biomedical focus. Patterns may differ in other fields.
- Crude feature classification. Title and abstract classification used regex pattern matching, which has inherent noise.
Finding 1: AI Overwhelmingly Cites Landmark Papers
The most striking finding is the sheer citation volume of AI-cited papers. These are not average papers, they are among the most cited in their fields. AI-cited papers had a median of 1,276 PubMed citations. Their citation-matched controls had a median of 493 (Mann-Whitney U=21,262, p<0.0001). A typical biomedical paper has about 4.
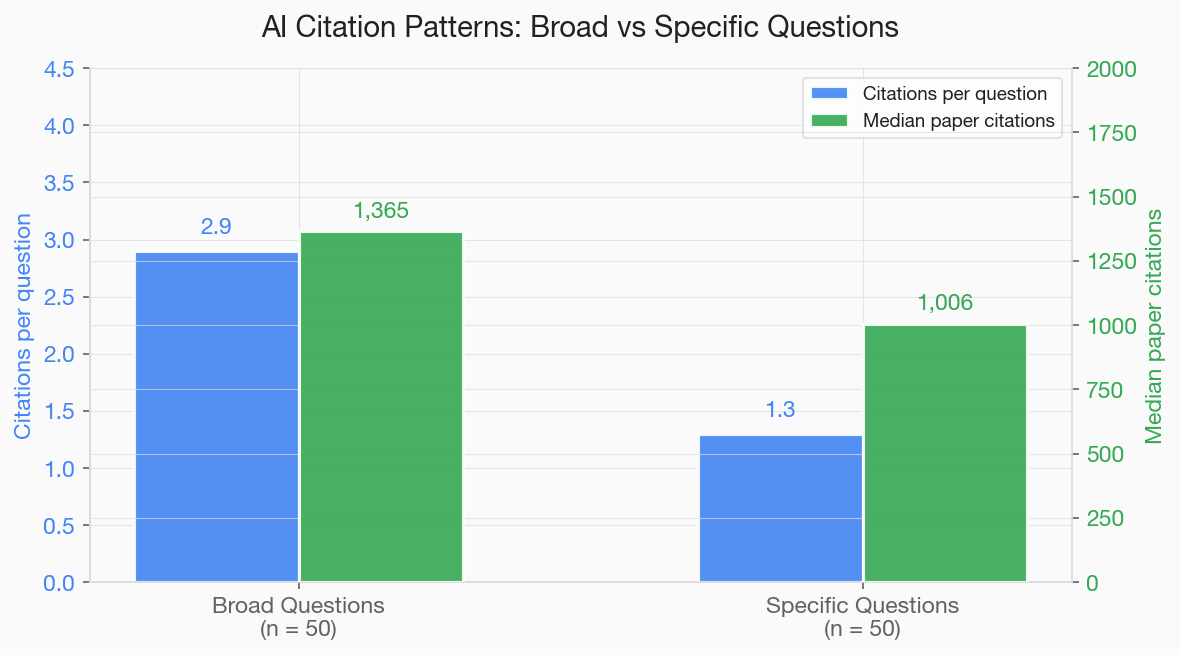
- Broad questions: Median PubMed citations per AI-cited paper: 1,365
- Specific questions: Median PubMed citations per AI-cited paper: 1,006
- 97.8% of papers cited in broad answers had 100+ PubMed citations
To put this in context: a typical biomedical paper accumulates about 4 citations over its lifetime. The papers AI cites are 250–340 times more cited than the average paper. AI is not sampling from the full distribution of published research, it is sampling from the extreme right tail.
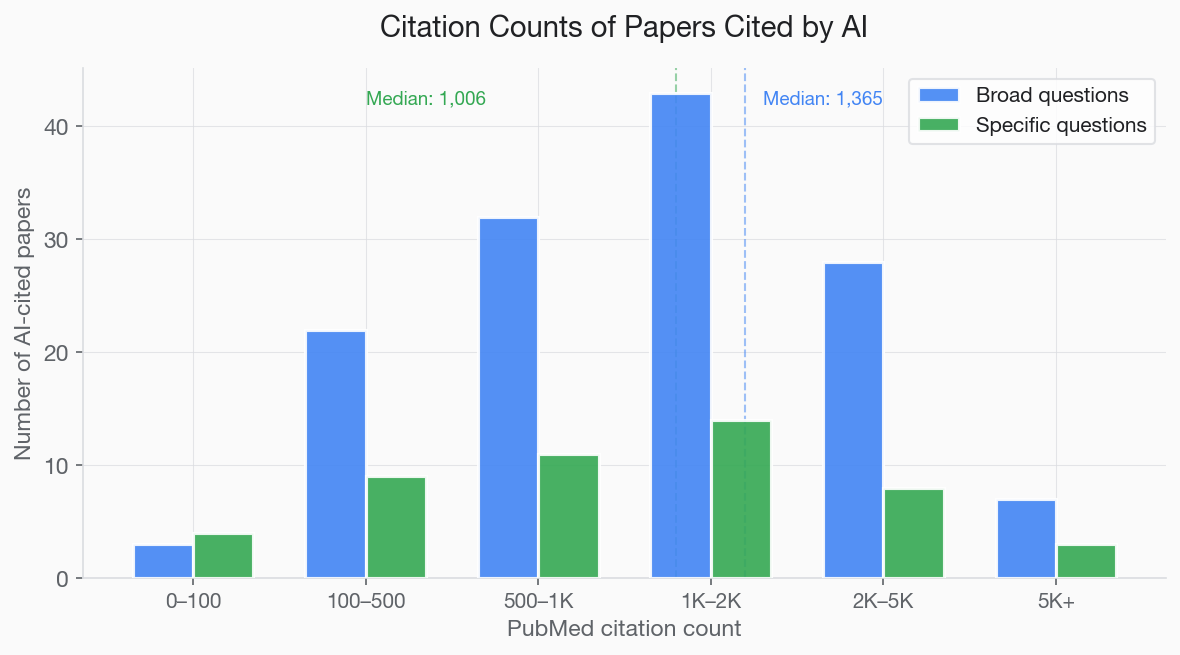
This finding has an uncomfortable implication: for broad overview questions, AI citation is essentially closed to papers that are not already highly cited. The model has learned that certain papers are canonical references for certain topics, and it reproduces that pattern. There is no mechanism for a new paper with 10 citations to break into this pool for a broad question like "How does CRISPR work?"
AI language models learn from training corpora that include textbooks, review articles, and course materials. These sources repeatedly reference the same landmark papers. The model internalises this pattern: when asked to explain a topic, it reproduces the citations that its training data most commonly associated with that topic. This creates a self-reinforcing loop that mirrors the Matthew effect in academia, the rich get richer.
Finding 2: Extreme Journal Concentration
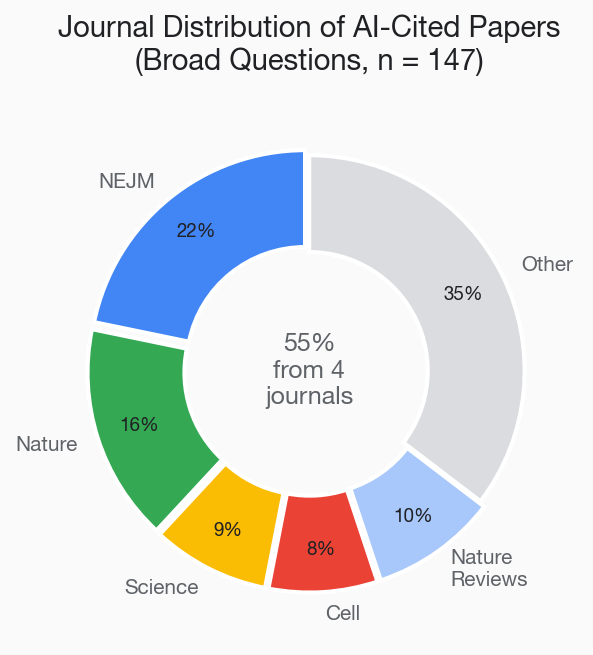
The journal distribution of AI citations is even more concentrated than the citation counts suggest. More than half of all citations came from just four journals:
- The New England Journal of Medicine: 32 citations (highest of any journal)
- Nature: 24 citations
- Science: 13 citations
- Cell: 12 citations
Together, these four journals accounted for 55% of all AI citations in our sample. Add the Nature Reviews family (Nature Reviews Immunology, Nature Reviews Cancer, etc.) and the figure rises further, with 14 additional citations from reviews journals alone.
This means that the vast majority of biomedical journals, and by extension the vast majority of biomedical papers, are functionally invisible to AI when it answers broad overview questions. If your paper was published in a speciality journal with moderate impact, it is unlikely to be cited in response to a general question about your field, regardless of its quality.
This is not a judgement about journal quality. It reflects the structure of AI training data, which over-represents high-profile journals because they are more frequently cited in the textbooks, reviews, and educational materials that make up the training corpus.
Finding 3: Specific Questions Produce Fewer Citations, and More Gaps
The difference between broad and specific questions was one of the most practically important findings.
- Broad questions: 2.9 citations per answer on average
- Specific questions: 1.3 citations per answer on average
- Approximately 20 of the 50 specific questions received answers with no cited paper at all
When the AI was asked broad questions ("How does immunotherapy work?"), it confidently cited 2–4 landmark papers per response. When asked specific questions ("What is the binding affinity of nivolumab to PD-1?"), it frequently answered from what appeared to be generalised knowledge with no specific citation, or cited only a single paper.
The 20 specific questions that received no citations are particularly interesting. The AI provided answers, sometimes accurate, sometimes vague, but did not name a source paper. These are questions where the AI needed a paper to cite but did not have one.
The gaps in specific technical questions are where researchers can break through. For these questions, you are not competing against Nature and NEJM reviews with thousands of citations. You are filling a void. If your paper is the definitive, clearly structured answer to a specific technical question, AI systems will learn to cite it as training data expands.
Finding 4: AI Citations Are Overwhelmingly Real
A common concern about AI citations is hallucination, the fabrication of plausible-sounding but nonexistent papers. We tested this directly by verifying every cited DOI against PubMed.
- Broad questions: 94.4% of cited DOIs matched real PubMed-indexed papers
- Specific questions: 81.7% of cited DOIs matched real PubMed-indexed papers
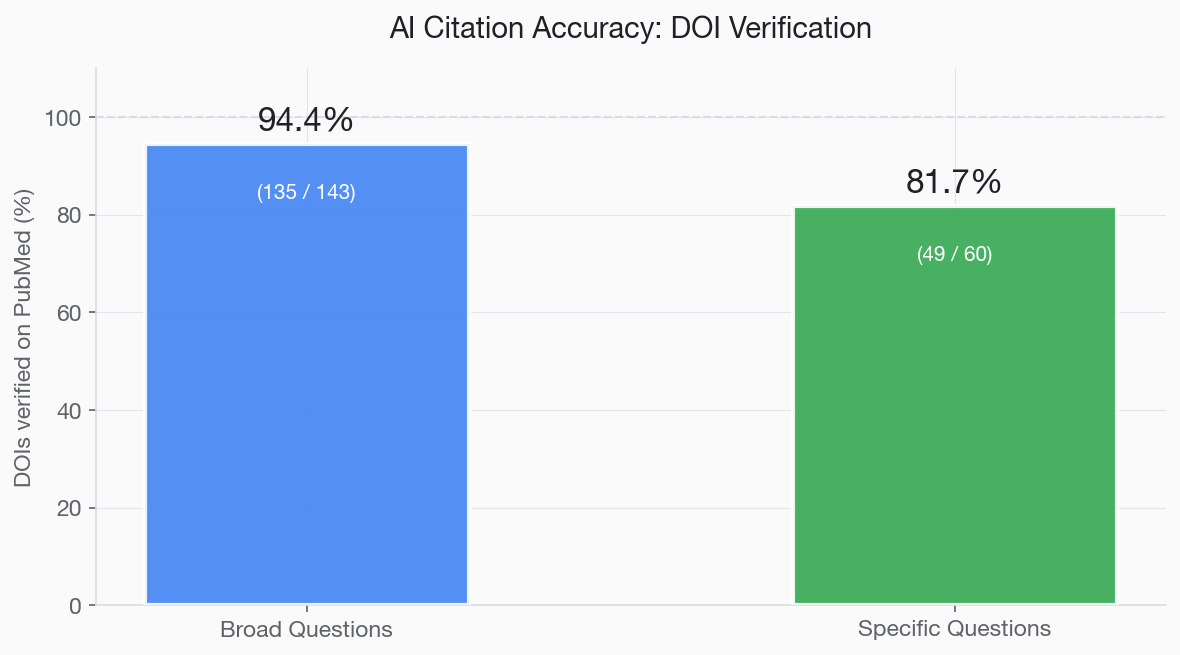
The pattern makes sense: when citing a landmark paper that appeared thousands of times in its training data (such as a major NEJM trial), the AI has seen the correct DOI repeatedly and reproduces it accurately. When citing a less prominent paper for a specific question, it is more likely to confuse details or generate a partially fabricated reference.
The 5.6% hallucination rate for broad questions is low but not zero. Researchers and readers should always verify AI-provided citations, just as they would verify any reference. But the narrative that AI "just makes up papers" is overstated, at least for well-known biomedical literature.
Finding 5: Publication Year Bias Toward 2015–2019
AI citations are not uniformly distributed across publication years. There is a clear peak in the mid-to-late 2010s:
- Before 2005: Very few citations (mostly foundational discoveries)
- 2005–2014: Moderate representation
- 2015–2019: Peak period, accounting for 49% of all broad-question citations
- 2020–2022: Declining representation
- After 2022: Almost no citations
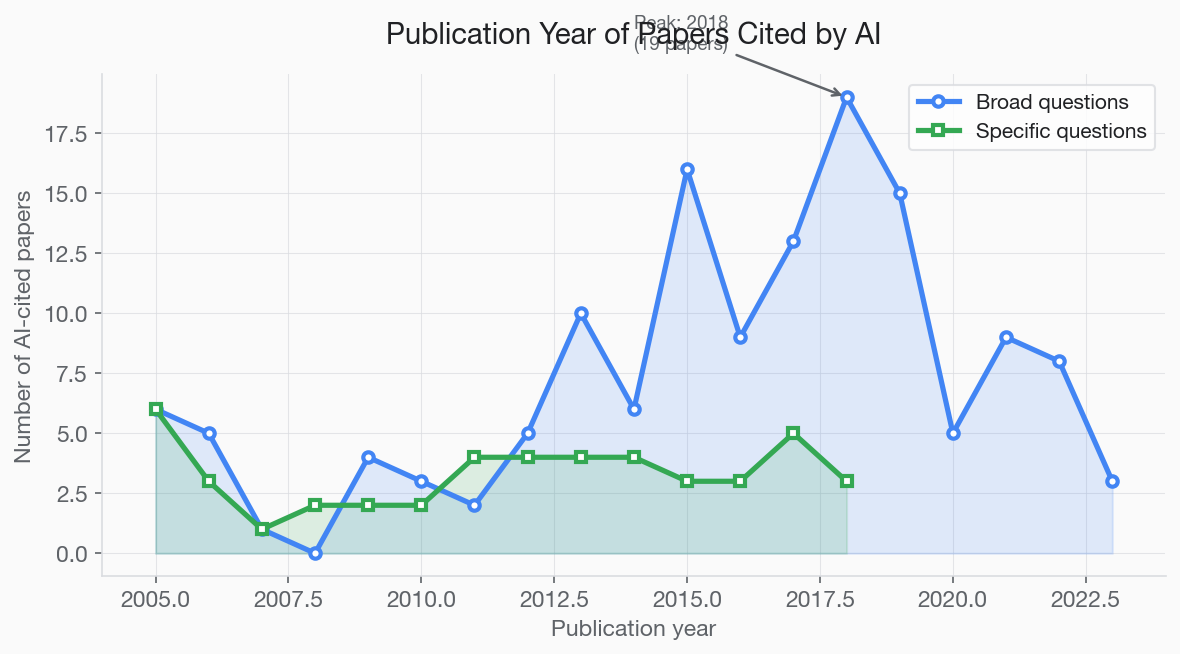
This distribution likely reflects two overlapping factors. First, training data cutoff: the model's training data has a recency boundary, and papers published after that boundary are less represented. Second, citation accumulation: papers from 2015–2019 have had enough time to accumulate the high citation counts that make them "landmark" papers, but are recent enough to cover current biology.
This creates a temporal bias that disadvantages both very old foundational work (which may be cited indirectly rather than directly) and very recent papers (which have not yet accumulated enough citations or training-data presence).
Finding 6: The Case-Control Test: Content Features Vanish
This is the most important finding, and the one that required the most methodological rigour to establish.
Our initial analysis (without citation-matched controls) appeared to show strong associations between content features and AI citation: open access +19pp, specific entities +21pp, declarative openings +20pp. These numbers looked publishable.
But they were misleading. All of these features correlate with high citation count. Highly cited papers are more likely to be open access (because funders pay for it), have more specific entities in their titles (because they’re about specific discoveries), and have declarative openings (because high-profile journals encourage direct language). The features were proxies for citation count, not independent predictors of AI citation.
To test this, we built a citation-matched control group: 172 topically similar papers from the same fields that the AI did not cite, matched as closely as possible on citation count. We then compared every content feature between AI-cited and control papers using chi-square tests and Mann-Whitney U tests.
PMC open access: 58.7% vs 54.1%, p=0.46, not significant
Structured abstract: 26.9% vs 29.1%, p=0.75, not significant
Declarative title: 12.6% vs 8.1%, p=0.24, not significant
Entity in title: 44.9% vs 39.5%, p=0.37, not significant
Review article: 21.0% vs 28.5%, p=0.14, not significant
Declarative abstract opening: 59.9% vs 54.1%, p=0.33, not significant
All chi-square tests, two-sided. No feature reached p < 0.05.
The logistic regression tells the same story even more clearly:
Model 1 (citation count only): McFadden pseudo-R² = 12.4%
Model 2 (citation count + all content features): pseudo-R² = 13.8%
Content features add just 1.5 percentage points of additional variance
Features tested: open access, structured abstract, entity in title, declarative title, review status, author count. None individually significant after controlling for log citation count.
In plain language: citation count explains almost everything. Content features explain almost nothing on top of that.
What This Actually Means for Researchers
We want to be direct about the implications, including the uncomfortable ones.
You cannot optimise your way into AI citation
The GEO literature for commercial content suggests that formatting, entity density, and structural choices can boost AI citation. Our data shows that for academic papers, this does not apply. No content feature we measured, open access, abstract structure, title type, entity density, independently predicts AI citation once you control for citation count. The only path to AI citation is writing research that humans cite first.
But the gap opportunity is real
The most actionable finding from this study is not about the features of cited papers, it’s about the questions where AI cites nothing. When asked specific technical questions, the AI frequently answered from general knowledge with no paper cited at all. These gaps are where new research can break through. You are not trying to displace a Nature review with 5,000 citations. You are filling a void where no citable answer exists yet.
The cold-start problem
There is a circularity: you need citations to get cited by AI, but AI citation could help you get citations. New papers face a cold-start problem that is even more severe in AI than in traditional search, because AI does not have a “long tail” of results, it either cites your paper or it does not. Preprints partly break this loop: they enter the citation graph 6–12 months before the journal version, and live-search AI systems (Perplexity, ChatGPT browsing) can surface them. See bioRxiv SEO and our March 2026 preprint-discovery analysis for the evidence.
Practical Recommendations
Based on our data, here is what we can honestly recommend:
- Focus on human citations first. Our data is unambiguous: citation count is the dominant signal for AI citation. Everything that increases human citations, publishing in visible journals, promoting your work, writing with demonstrably higher readability, adding a plain-language summary, also increases the probability of AI citation. There is no shortcut.
- Identify specific questions AI cannot answer. Ask Claude, ChatGPT, or Perplexity the precise question your paper answers. If the AI gives a vague answer with no citation, you have found a gap. Write your paper to fill it.
- Use the terms people search for in your title. While title type did not independently predict AI citation in our controlled analysis, title keywords still determine whether your paper matches a query at all. Use the exact terms your audience types.
- Make your paper accessible. Open access did not reach statistical significance in our case-control analysis (p=0.46), but the direction was positive (+4.6pp), and the logic remains sound: AI training data includes more open-access content. This is good practice regardless of AI.
- Build co-citation networks with landmark papers. If your paper cites and extends a canonical study, and is cited alongside it by others, you become associated with that landmark in training data.
How This Compares to Existing GEO Research
Aggarwal et al. (2024) introduced GEO and showed that adding citations, statistics, and authoritative language to web content increased AI visibility by up to 40% (doi:10.1145/3637528.3671900). Kevin Indig’s analysis of 1.2 million ChatGPT responses (victorinollc.com) found that declarative openings showed +14% citation lift for commercial content, and that signals are vertical-specific.
Our finding extends this picture: the academic vertical follows different rules entirely. For commercial web content, structural optimisation matters. For academic papers, it does not, at least not independently of citation count. The reason is likely that academic papers compete in a much more hierarchical landscape: a small number of landmark papers dominate each topic, and AI has learned this hierarchy from the training data itself.
This means the GEO advice circulating in marketing circles, “add statistics,” “use declarative headings,” “increase entity density”, should not be directly applied to academic papers without evidence. Our data suggests it would not help.
References
- Aggarwal P, Murahari V, Rajpurohit T, et al. GEO: Generative engine optimization. Proc ACM KDD. 2024. doi:10.1145/3637528.3671900
- Letchford A, Moat HS, Preis T. The advantage of short paper titles. R Soc Open Sci. 2015;2(8):150266. doi:10.1098/rsos.150266
- Paiva CE, Lima JPSN, Paiva BSR. Articles with short titles describing the results are cited more often. Clinics. 2012;67(5):509–513. doi:10.6061/clinics/2012(05)17
- Indig K. Analysis of 1.2 million ChatGPT responses: citation and source patterns. Victorino LLC. victorinollc.com
- SurferSEO. How LLMs cite sources: an analysis of AI citation behaviour. SurferSEO. surferseo.com
Frequently Asked Questions
Does AI cite real papers or make them up?
In our study, 94.4% of papers cited in response to broad biomedical questions had valid DOIs that matched real PubMed-indexed articles. For specific technical questions, accuracy was 81.7%. AI systems do occasionally hallucinate citations, fabricating plausible-sounding but nonexistent papers, but the majority of citations are real, particularly when the AI is citing well-known landmark papers.
How many citations does a paper need to get cited by AI?
In our sample, the median PubMed citation count for AI-cited papers was 1,365 for broad questions and 1,006 for specific questions. 97.8% of papers cited in broad answers had 100+ citations. However, for specific technical questions where no landmark paper exists, AI systems will cite less well-known papers, or cite nothing at all. These gaps represent opportunities for researchers.
Which journals do AI systems cite most?
In our study, 55% of all AI citations came from just four journals: The New England Journal of Medicine (32 citations), Nature (24), Science (13), and Cell (12). The Nature Reviews family contributed 14 additional citations. This extreme concentration means papers in most journals are functionally invisible to AI citation.
Can a new paper with few citations get cited by AI?
Rarely for broad questions, our case-control analysis shows that citation count is the dominant predictor of AI citation, and content features like open access, title type, and abstract structure do not independently help (all p > 0.05). However, for specific technical questions where no landmark paper exists, AI either cites less prominent papers or cites nothing at all. These gaps are where new research can realistically break through.
How is AI citation different from Google Scholar ranking?
Google Scholar ranks papers for specific search queries, meaning niche papers can rank well for niche terms. AI citation is more winner-take-all: for broad questions, AI pulls from a small pool of landmark papers regardless of how the question is phrased. However, for specific questions, AI behaves more like a search engine, it needs a paper that directly answers the question, and title keywords and abstract structure matter. The biggest difference is that AI citation has no long tail: a paper either gets cited or it does not.
Ready to optimise your paper for AI and search visibility?
We optimise your title, abstract, keywords, readability, and metadata for Google Scholar, PubMed, and AI search engines.
Submit your paper →